Run a Pipeline on Arrikto vGPUs using the Kale SDK¶
Without Kiwi, each step of a Kubeflow pipeline requiring an NVIDIA GPU occupies a whole GPU. This means that in order for N independent steps to run in parallel, we would need N GPUs. Kiwi enables multiple steps of a Kubeflow pipeline to run in parallel on the same GPU.
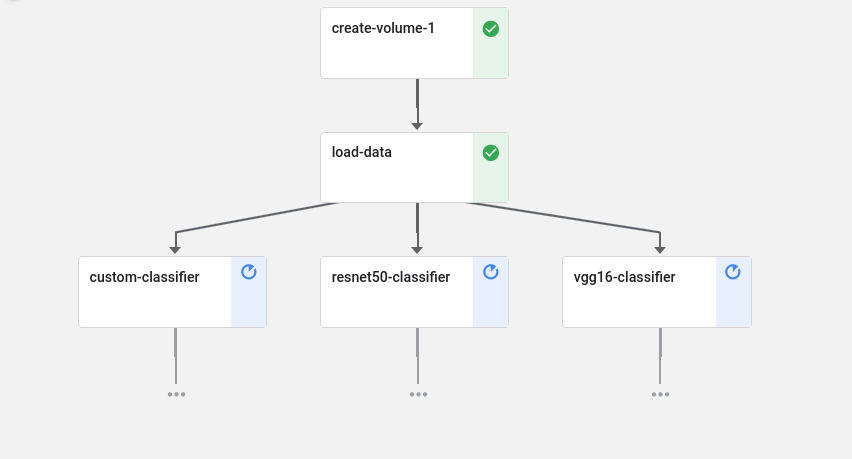
In this section you will use the Kale SDK to deploy a Kubeflow pipeline whose GPU steps will all run in parallel on the same physical device through Kiwi. You will run Kaggle’s dog breed classification example that classifies images of dogs according to their breed.
Overview
What You’ll Need¶
- An existing Kiwi deployment on your Kubernetes cluster.
Procedure¶
Create a new notebook server using the Kale Tensorflow GPU Docker image. The image will have the following naming scheme:
gcr.io/arrikto/jupyter-kale-gpu-tf-py38:<IMAGE_TAG>Note
The
<IMAGE_TAG>varies based on the MiniKF or EKF release.Note
You do not need to add an Arrikto vGPU to the notebook server when you create it in the Jupyter Web App. You will not run any GPU work from inside that notebook server. You will only create the Kubeflow pipeline, whose steps are going to use Arrikto vGPUs.
Connect to the server, open a terminal, and install the required packages:
$ pip3 install --user pillow==7.2.0 tensorflow==2.6.2 matplotlib==3.3.1 fastapi==0.76.0Download and extract the required dog images:
$ wget https://s3-us-west-1.amazonaws.com/udacity-aind/dog-project/dogImages.zip \ > && unzip -qo dogImages.zip \ > && rm dogImages.zipCreate a new Python file and name it
kiwi_dogbreed.py:$ touch kiwi_dogbreed.pyCopy and paste the following code inside
kiwi_dogbreed.py, or download it:kiwi_dogbreed.py
1 # Copyright © 2021-2022 Arrikto Inc. All Rights Reserved. 2 3 """Kiwi example using the Kale SDK. 4-169 4 5 This script creates an ML pipeline that classifies dog images 6 and runs in parallel on the same Kiwi-enabled GPU 7 """ 8 9 from kale.types import MarshalData 10 import tensorflow as tf 11 12 from tensorflow.keras.preprocessing.image import ImageDataGenerator 13 from kubernetes.client import (V1Affinity, V1PodAffinity, V1PodAffinityTerm, 14 V1LabelSelector) 15 16 from kale.sdk import pipeline, step 17 from PIL import ImageFile 18 19 ImageFile.LOAD_TRUNCATED_IMAGES = True 20 21 affinity = V1Affinity(pod_affinity=V1PodAffinity( 22 required_during_scheduling_ignored_during_execution=[ 23 V1PodAffinityTerm( 24 topology_key="kubernetes.io/hostname", 25 label_selector=V1LabelSelector( 26 match_labels={"app": "dogbreed"}))])) 27 28 29 @step(name="load-data") 30 def load_data(img_size: int = 224, batch_size: int = 32): 31 def get_train_generator(): 32 data_datagen = ImageDataGenerator(rescale=1. / 255, 33 width_shift_range=.2, 34 height_shift_range=.2, 35 brightness_range=[0.5, 1.5], 36 horizontal_flip=True) 37 return data_datagen.flow_from_directory( 38 "dogImages/train/", target_size=(img_size, img_size), 39 batch_size=batch_size) 40 41 def get_valid_generator(): 42 data_datagen = ImageDataGenerator(rescale=1. / 255) 43 return data_datagen.flow_from_directory( 44 "dogImages/valid/", target_size=(img_size, img_size), 45 batch_size=batch_size) 46 47 def get_test_generator(): 48 data_datagen = ImageDataGenerator(rescale=1. / 255) 49 return data_datagen.flow_from_directory( 50 "dogImages/test/", target_size=(img_size, img_size), 51 batch_size=batch_size) 52 53 return get_train_generator, get_valid_generator, get_test_generator 54 55 56 @step(name="custom-classifier", 57 deploy_config={"limits": {"arrikto.com/gpu": "1"}}) 58 def custom_classifier(get_train_generator: MarshalData, 59 get_valid_generator: MarshalData, epochs: int = 2, 60 img_size: int = 224, number_of_nodes: int = 512, 61 lr: float = 0.001): 62 model = tf.keras.models.Sequential( 63 [tf.keras.layers.Conv2D(16, 3, activation="relu", 64 input_shape=(img_size, img_size, 3)), 65 tf.keras.layers.MaxPool2D(), 66 tf.keras.layers.Conv2D(32, 3, activation="relu"), 67 tf.keras.layers.MaxPool2D(), 68 tf.keras.layers.Conv2D(64, 3, activation="relu"), 69 tf.keras.layers.MaxPool2D(), 70 tf.keras.layers.GlobalAveragePooling2D(), 71 tf.keras.layers.Dense(int(number_of_nodes), activation="relu"), 72 tf.keras.layers.Dense(133, activation="softmax")]) 73 74 model.compile( 75 optimizer=tf.optimizers.Adam(learning_rate=float(lr)), 76 loss=tf.losses.categorical_crossentropy, 77 metrics=["accuracy"] 78 ) 79 80 train_generator = get_train_generator() 81 valid_generator = get_valid_generator() 82 83 tb_callback = tf.keras.callbacks.TensorBoard( 84 log_dir="custom_classifier_logs") 85 86 model.fit(train_generator, epochs=epochs, validation_data=valid_generator, 87 callbacks=[tb_callback]) 88 89 90 @step(name="vgg16-classifier", 91 deploy_config={"limits": {"arrikto.com/gpu": "1"}}) 92 def vgg16_classifier(get_train_generator: MarshalData, 93 get_valid_generator: MarshalData, epochs: int = 2, 94 img_size: int = 224, lr: float = 0.001): 95 vgg_body = tf.keras.applications.VGG16( 96 weights="imagenet", 97 include_top=False, 98 input_shape=(img_size, img_size, 3) 99 ) 100 101 vgg_body.trainable = False 102 103 inputs = tf.keras.layers.Input(shape=(img_size, img_size, 3)) 104 x = vgg_body(inputs, training=False) 105 x = tf.keras.layers.GlobalAveragePooling2D()(x) 106 outputs = tf.keras.layers.Dense(133, activation="softmax")(x) 107 vgg_model = tf.keras.Model(inputs, outputs) 108 109 vgg_model.summary() 110 111 vgg_model.compile( 112 optimizer=tf.optimizers.Adam(learning_rate=float(lr)), 113 loss=tf.losses.categorical_crossentropy, 114 metrics=["accuracy"] 115 ) 116 117 train_generator = get_train_generator() 118 valid_generator = get_valid_generator() 119 120 vgg_model.fit(train_generator, epochs=epochs, 121 validation_data=valid_generator) 122 123 124 @step(name="resnet50-classifier", 125 deploy_config={"limits": {"arrikto.com/gpu": "1"}}) 126 def resnet50_classifier(get_train_generator: MarshalData, 127 get_valid_generator: MarshalData, epochs: int = 2, 128 img_size: int = 224, lr: float = 0.001): 129 resnet_body = tf.keras.applications.ResNet50V2( 130 weights="imagenet", 131 include_top=False, 132 input_shape=(img_size, img_size, 3) 133 ) 134 135 resnet_body.trainable = False 136 137 inputs = tf.keras.layers.Input(shape=(img_size, img_size, 3)) 138 139 x = resnet_body(inputs, training=False) 140 x = tf.keras.layers.Flatten()(x) 141 outputs = tf.keras.layers.Dense(133, activation="softmax")(x) 142 143 resnet_model = tf.keras.Model(inputs, outputs) 144 145 resnet_model.compile( 146 optimizer=tf.optimizers.Adam(learning_rate=float(lr)), 147 loss=tf.losses.categorical_crossentropy, 148 metrics=["accuracy"] 149 ) 150 151 train_generator = get_train_generator() 152 valid_generator = get_valid_generator() 153 154 resnet_model.fit(train_generator, epochs=epochs, 155 validation_data=valid_generator) 156 157 158 @pipeline(name="dog-classifier", experiment="kiwi-tutorial", 159 deploy_config={"affinity": affinity, "labels": {"app": "dogbreed"}}, 160 autosnapshot=False) 161 def dog_classifier(epochs: int = 2, lr: float = 6e-4, batch_size: int = 32, 162 img_size: int = 224, number_of_nodes: int = 512): 163 train_generator, valid_generator, junk = load_data(img_size, batch_size) 164 custom_classifier(train_generator, valid_generator, epochs, img_size, 165 number_of_nodes, lr) 166 vgg16_classifier(train_generator, valid_generator, epochs, img_size, lr) 167 resnet50_classifier(train_generator, valid_generator, epochs, img_size, lr) 168 169 170 if __name__ == "__main__": 171 dog_classifier(epochs=4, lr=6e-4, batch_size=32, 172 img_size=224, number_of_nodes=512) In this code sample, we define three distinct pipeline steps, each of which trains an ML model on distinguishing dog breeds:
custom-classifier,vgg16-classfier, andresnet50-classifier.We then run the pipeline, ensuring (via Pod Affinities) that all the steps run on the same Kiwi-enabled NVIDIA GPU. We do this just for illustration purposes.
To showcase Kiwi’s GPU sharing capabilities in a multi-node GPU cluster, we first create a Pod Affinity object using the following snippet from our example program:
affinity = V1Affinity(pod_affinity=V1PodAffinity( required_during_scheduling_ignored_during_execution=[ V1PodAffinityTerm topology_key="kubernetes.io/hostname", label_selector=V1LabelSelector( match_labels={"app": "dogbreed"}))]))Then we attach this Affinity to each step (Pod) of the pipeline by providing it as an argument when creating the pipeline using the following snippet:
@pipeline(name="dog-classifier", experiment="kiwi-tutorial", deploy_config={"affinity": affinity, "labels": {"app": "dogbreed"}}, autosnapshot=False)Deploy and run your code as a KFP pipeline:
$ python3 -m kale kiwi_dogbreed.py --kfpView the pipeline run via the Runs tab on the Kubeflow UI. You will eventually see all three GPU steps running in parallel on the same physical GPU.
Note
The GPU steps are running on the same physical GPU because we forced them to run on the same node using Pod Affinities. Since Kiwi only uses one physical GPU per node, they are all running on that GPU.