
Example: Create a TensorFlow Keras Distributed KFP Step with the Kale SDK¶
This section will guide you through creating a TF Keras distributed KFP step on Kubeflow, using the Kale SDK and the Kubeflow Training Operator.
Overview
What You’ll Need¶
- An Arrikto EKF or MiniKF deployment.
- The Kale TensorFlow Docker image.
- An understanding of how the Kale SDK works.
Procedure¶
Create a new Notebook server using the Kale TensorFlow Docker image. The image will have the following naming scheme:
gcr.io/arrikto/jupyter-kale-gpu-tf-py38:<IMAGE_TAG>Note
The
<IMAGE_TAG>varies based on the MiniKF or EKF release.This is not the default Kale image, so you must carefully choose it from the dropdown menu.
Note
If you want to have access to a GPU device, you must specifically request one or more from the Jupyter Web App UI. For this user guide, access to a GPU device is not required.
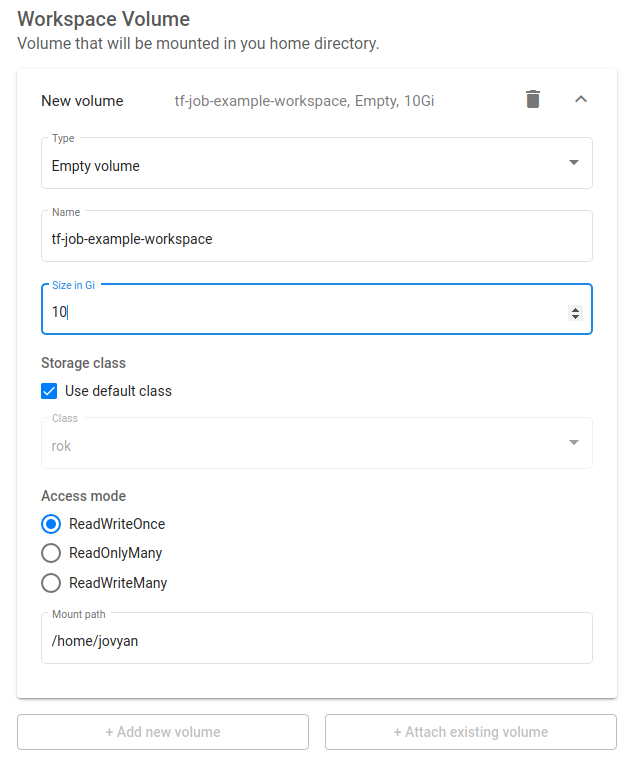
Increase the size of the workspace volume to 10GB:
Connect to the server, open a terminal, and install the
tensorflow-datasetspackage:$ pip3 install --user tensorflow-datasetsCreate a new python file and name it
kale_dist.py:$ touch kale_dist.pyCopy and paste the following code inside
kale_dist.py:starter.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4 5 This script creates a TF Keras distributed KFP step to solve MNIST. 6 """ 7 8 from kale.sdk import pipeline, step 9 10 11 @step(name="load_data") 12 def load_data(): 13 """Create the Training dataset.""" 14 def _data_fn(): 15 import tensorflow as tf 16 import tensorflow_datasets as tfds 17 18 buffer_size = 10000 19 batch_size = 128 20 21 def scale(image, label): 22 """Scale MNIST data from (0, 255] to (0., 1.].""" 23 image = tf.cast(image, tf.float32) 24 image /= 255 25 return image, label 26 27 datasets, _ = tfds.load(name='mnist', with_info=True, 28 as_supervised=True) 29 30 train_dataset = (datasets['train'] 31 .map(scale) 32 .cache() 33 .shuffle(buffer_size) 34 .repeat() 35 .batch(batch_size)) 36 37 return train_dataset 38 39 return _data_fn 40 41 42 @step(name="create_model") 43 def create_model(): 44 """Define the model.""" 45 def _create_model(): 46 import tensorflow as tf 47 48 model = tf.keras.models.Sequential() 49 model.add( 50 tf.keras.layers.Conv2D(32, (3, 3), activation='relu', 51 input_shape=(28, 28, 1))) 52 model.add(tf.keras.layers.MaxPooling2D((2, 2))) 53 model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu')) 54 model.add(tf.keras.layers.MaxPooling2D((2, 2))) 55 model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu')) 56 model.add(tf.keras.layers.Flatten()) 57 model.add(tf.keras.layers.Dense(64, activation='relu')) 58 model.add(tf.keras.layers.Dense(10, activation='softmax')) 59 60 model.summary() 61 62 model.compile(optimizer='adam', 63 loss='sparse_categorical_crossentropy', 64 metrics=['accuracy']) 65 66 return model 67 68 return _create_model 69 70 71 @pipeline(name="fmnist", experiment="kale-dist") 72 def ml_pipeline(): 73 """Run the ML pipeline.""" 74 load_data() 75 create_model() 76 77 78 if __name__ == "__main__": 79 ml_pipeline() This script creates a pipeline with two steps.
- The first step defines a function which loads the MNIST dataset and prepares it for training.
- The second step returns a function that defines the architecture of a TF Keras model.
Distribute the training job over multiple GPU devices. The following snippet summarizes the changes in code:
tfjob.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4-5 4 5 This script creates a TF Keras distributed KFP step to solve MNIST. 6 """ 7 8 from kale.sdk import pipeline, step 9 + from kale.distributed import tf as kale_tf 10 11 12 @step(name="load_data") 13-68 13 def load_data(): 14 """Create the Training dataset.""" 15 def _data_fn(): 16 import tensorflow as tf 17 import tensorflow_datasets as tfds 18 19 buffer_size = 10000 20 batch_size = 128 21 22 def scale(image, label): 23 """Scale MNIST data from (0, 255] to (0., 1.].""" 24 image = tf.cast(image, tf.float32) 25 image /= 255 26 return image, label 27 28 datasets, _ = tfds.load(name='mnist', with_info=True, 29 as_supervised=True) 30 31 train_dataset = (datasets['train'] 32 .map(scale) 33 .cache() 34 .shuffle(buffer_size) 35 .repeat() 36 .batch(batch_size)) 37 38 return train_dataset 39 40 return _data_fn 41 42 43 @step(name="create_model") 44 def create_model(): 45 """Define the model.""" 46 def _create_model(): 47 import tensorflow as tf 48 49 model = tf.keras.models.Sequential() 50 model.add( 51 tf.keras.layers.Conv2D(32, (3, 3), activation='relu', 52 input_shape=(28, 28, 1))) 53 model.add(tf.keras.layers.MaxPooling2D((2, 2))) 54 model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu')) 55 model.add(tf.keras.layers.MaxPooling2D((2, 2))) 56 model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu')) 57 model.add(tf.keras.layers.Flatten()) 58 model.add(tf.keras.layers.Dense(64, activation='relu')) 59 model.add(tf.keras.layers.Dense(10, activation='softmax')) 60 61 model.summary() 62 63 model.compile(optimizer='adam', 64 loss='sparse_categorical_crossentropy', 65 metrics=['accuracy']) 66 67 return model 68 69 return _create_model 70 71 72 + @step(name="model_training") 73 + def distribute_training(model_fn, data_fn): 74 + """Train the model.""" 75 + tfjob = kale_tf.distribute( 76 + model_fn=model_fn, 77 + train_data_fn=data_fn, 78 + epochs=4, 79 + number_of_processes=2, 80 + cuda=True, 81 + fit_kwargs={"steps_per_epoch": 70} 82 + ) 83 + 84 + return tfjob.name 85 + 86 + 87 @pipeline(name="fmnist", experiment="kale-dist") 88 def ml_pipeline(): 89 """Run the ML pipeline.""" 90 - load_data() 91 - create_model() 92 + data_fn = load_data() 93 + model_fn = create_model() 94 + distribute_training(model_fn, data_fn) 95 96 97 if __name__ == "__main__": 98 ml_pipeline() See also
To find out more about the process the
distributefunction follows, head to the corresponding section of the TF Keras distributed with Kale guide:Note
If you want to distribute your model across multiple CPU cores, you can set the
cudaargument toFalse. By default, Kale will launch two processes (the minimum number of processes required by theTFJobCR), on two different GPU devices.Monitor the
TFJobCR you submitted. The following snippet summarizes the changes in code:final.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4 5 This script creates a TF Keras distributed KFP step to solve MNIST. 6 """ 7 + 8 + import time 9 + 10 + from kubernetes.client.rest import ApiException 11 12 from kale.sdk import pipeline, step 13 from kale.distributed import tf as kale_tf 14-87 14 15 16 @step(name="load_data") 17 def load_data(): 18 """Create the Training dataset.""" 19 def _data_fn(): 20 import tensorflow as tf 21 import tensorflow_datasets as tfds 22 23 buffer_size = 10000 24 batch_size = 128 25 26 def scale(image, label): 27 """Scale MNIST data from (0, 255] to (0., 1.].""" 28 image = tf.cast(image, tf.float32) 29 image /= 255 30 return image, label 31 32 datasets, _ = tfds.load(name='mnist', with_info=True, 33 as_supervised=True) 34 35 train_dataset = (datasets['train'] 36 .map(scale) 37 .cache() 38 .shuffle(buffer_size) 39 .repeat() 40 .batch(batch_size)) 41 42 return train_dataset 43 44 return _data_fn 45 46 47 @step(name="create_model") 48 def create_model(): 49 """Define the model.""" 50 def _create_model(): 51 import tensorflow as tf 52 53 model = tf.keras.models.Sequential() 54 model.add( 55 tf.keras.layers.Conv2D(32, (3, 3), activation='relu', 56 input_shape=(28, 28, 1))) 57 model.add(tf.keras.layers.MaxPooling2D((2, 2))) 58 model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu')) 59 model.add(tf.keras.layers.MaxPooling2D((2, 2))) 60 model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu')) 61 model.add(tf.keras.layers.Flatten()) 62 model.add(tf.keras.layers.Dense(64, activation='relu')) 63 model.add(tf.keras.layers.Dense(10, activation='softmax')) 64 65 model.summary() 66 67 model.compile(optimizer='adam', 68 loss='sparse_categorical_crossentropy', 69 metrics=['accuracy']) 70 71 return model 72 73 return _create_model 74 75 76 @step(name="model_training") 77 def distribute_training(model_fn, data_fn): 78 """Train the model.""" 79 tfjob = kale_tf.distribute( 80 model_fn=model_fn, 81 train_data_fn=data_fn, 82 epochs=4, 83 number_of_processes=2, 84 cuda=True, 85 fit_kwargs={"steps_per_epoch": 70} 86 ) 87 88 return tfjob.name 89 90 91 + @step(name="monitor") 92 + def monitor(name): 93 + """Monitor the PyTorchJob CR.""" 94 + job = kale_tf.TFJob(name) 95 + while True: # Iterate if streaming logs raises an ApiException 96 + while True: 97 + cr = job.get() 98 + if (job.get_job_status() not in ["", "Created", "Restarting"] 99 + and (cr.get("status", {}) 100 + .get("replicaStatuses", {}) 101 + .get("Worker", {}))): 102 + break 103 + print("Job pending...") 104 + time.sleep(2) 105 + try: 106 + job.stream_logs() 107 + break 108 + except ApiException as e: 109 + print("Streaming the logs failed with: %s", str(e)) 110 + print("Retrying...") 111 + 112 + 113 @pipeline(name="fmnist", experiment="kale-dist") 114 def ml_pipeline(): 115 """Run the ML pipeline.""" 116 data_fn = load_data() 117 model_fn = create_model() 118 - distribute_training(model_fn, data_fn) 119 + name = distribute_training(model_fn, data_fn) 120 + monitor(name) 121 122 123 if __name__ == "__main__": 124 ml_pipeline() Optional
Delete the
TFJobCR after completion. The following snippet summarizes the changes in code:delete.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4-109 4 5 This script creates a TF Keras distributed KFP step to solve MNIST. 6 """ 7 8 import time 9 10 from kubernetes.client.rest import ApiException 11 12 from kale.sdk import pipeline, step 13 from kale.distributed import tf as kale_tf 14 15 16 @step(name="load_data") 17 def load_data(): 18 """Create the Training dataset.""" 19 def _data_fn(): 20 import tensorflow as tf 21 import tensorflow_datasets as tfds 22 23 buffer_size = 10000 24 batch_size = 128 25 26 def scale(image, label): 27 """Scale MNIST data from (0, 255] to (0., 1.].""" 28 image = tf.cast(image, tf.float32) 29 image /= 255 30 return image, label 31 32 datasets, _ = tfds.load(name='mnist', with_info=True, 33 as_supervised=True) 34 35 train_dataset = (datasets['train'] 36 .map(scale) 37 .cache() 38 .shuffle(buffer_size) 39 .repeat() 40 .batch(batch_size)) 41 42 return train_dataset 43 44 return _data_fn 45 46 47 @step(name="create_model") 48 def create_model(): 49 """Define the model.""" 50 def _create_model(): 51 import tensorflow as tf 52 53 model = tf.keras.models.Sequential() 54 model.add( 55 tf.keras.layers.Conv2D(32, (3, 3), activation='relu', 56 input_shape=(28, 28, 1))) 57 model.add(tf.keras.layers.MaxPooling2D((2, 2))) 58 model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu')) 59 model.add(tf.keras.layers.MaxPooling2D((2, 2))) 60 model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu')) 61 model.add(tf.keras.layers.Flatten()) 62 model.add(tf.keras.layers.Dense(64, activation='relu')) 63 model.add(tf.keras.layers.Dense(10, activation='softmax')) 64 65 model.summary() 66 67 model.compile(optimizer='adam', 68 loss='sparse_categorical_crossentropy', 69 metrics=['accuracy']) 70 71 return model 72 73 return _create_model 74 75 76 @step(name="model_training") 77 def distribute_training(model_fn, data_fn): 78 """Train the model.""" 79 tfjob = kale_tf.distribute( 80 model_fn=model_fn, 81 train_data_fn=data_fn, 82 epochs=4, 83 number_of_processes=2, 84 cuda=True, 85 fit_kwargs={"steps_per_epoch": 70} 86 ) 87 88 return tfjob.name 89 90 91 @step(name="monitor") 92 def monitor(name): 93 """Monitor the PyTorchJob CR.""" 94 job = kale_tf.TFJob(name) 95 while True: # Iterate if streaming logs raises an ApiException 96 while True: 97 cr = job.get() 98 if (job.get_job_status() not in ["", "Created", "Restarting"] 99 and (cr.get("status", {}) 100 .get("replicaStatuses", {}) 101 .get("Worker", {}))): 102 break 103 print("Job pending...") 104 time.sleep(2) 105 try: 106 job.stream_logs() 107 break 108 except ApiException as e: 109 print("Streaming the logs failed with: %s", str(e)) 110 print("Retrying...") 111 112 113 + @step(name="delete") 114 + def delete(name): 115 + """Delete the PyTorchJob CR.""" 116 + job = kale_tf.TFJob(name) 117 + while job.get_job_status() != "Succeeded": 118 + continue 119 + job.delete() 120 + 121 + 122 @pipeline(name="fmnist", experiment="kale-dist") 123 def ml_pipeline(): 124 """Run the ML pipeline.""" 125-125 125 data_fn = load_data() 126 model_fn = create_model() 127 name = distribute_training(model_fn, data_fn) 128 monitor(name) 129 + delete(name) 130 131 132 if __name__ == "__main__": 133 ml_pipeline() Important
After the completion of the training process, the controller will not remove the resources it creates. If you do not want to leave stale resources, you have to manually delete the CR by making the above changes in your code.
Optional
Produce a workflow YAML file that you can inspect:
$ python3 -m kale kale_dist.py --compileDeploy and run your code as a KFP pipeline:
$ python3 -m kale kale_dist.py --kfpNote
To see the complete list of arguments and their respective usage, run
python3 -m kale --help.Navigate to the Experiments (KFP) UI, click on your pipeline, and select the
model_trainingstep. Select the ML Metadata tab to view the logged model artifact in the Outputs section: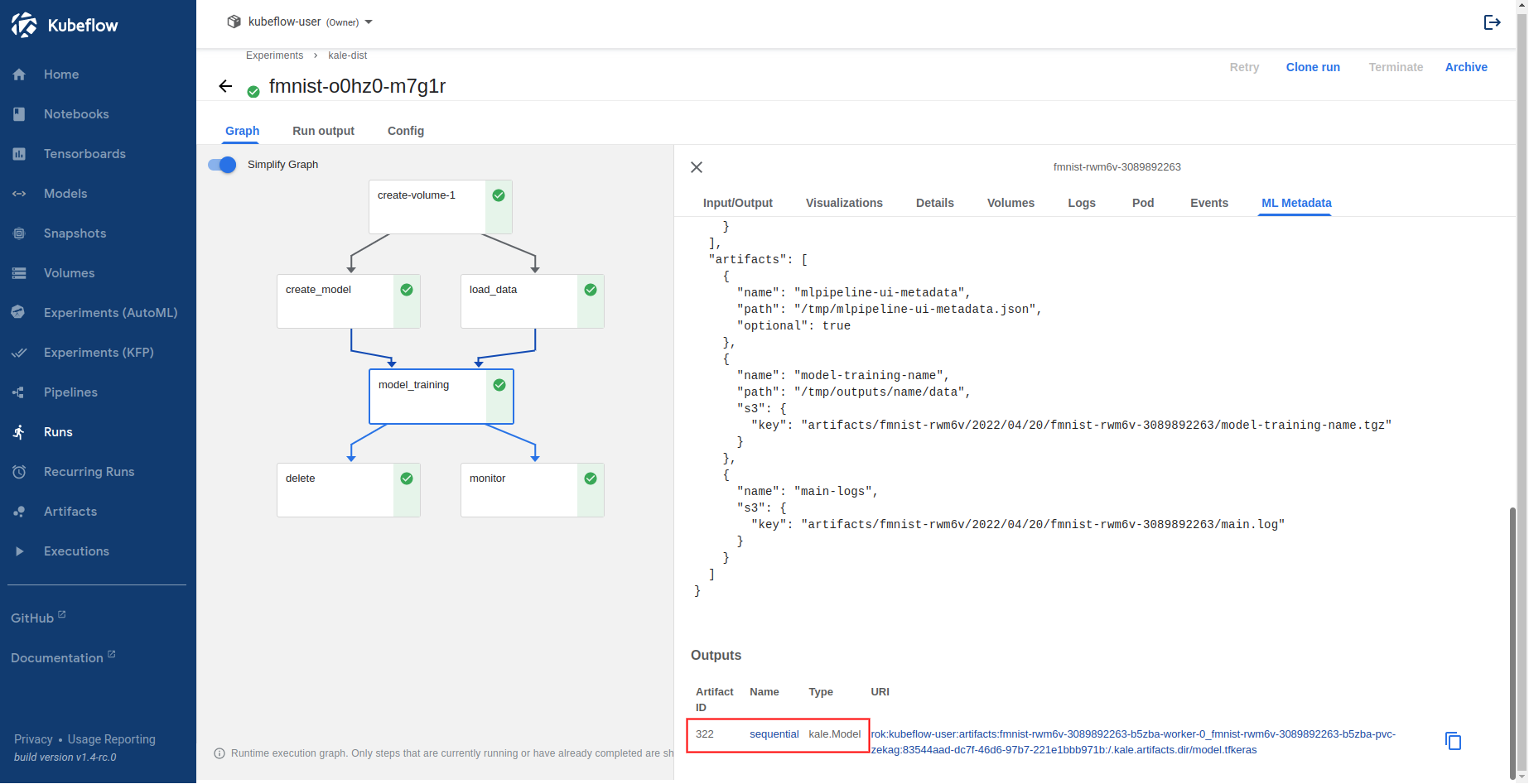
Click the
Nameattribute of the artifact to view the details of the model.
The ML Metadata UI includes general information about the model, such as its name, signature, computational graph, and the number of parameters, as well as other artifact metadata, such as tags, version, etc.